
1.1.什么是Cache?
Cache的一些架构演变,从简单的到复杂的通用架构.
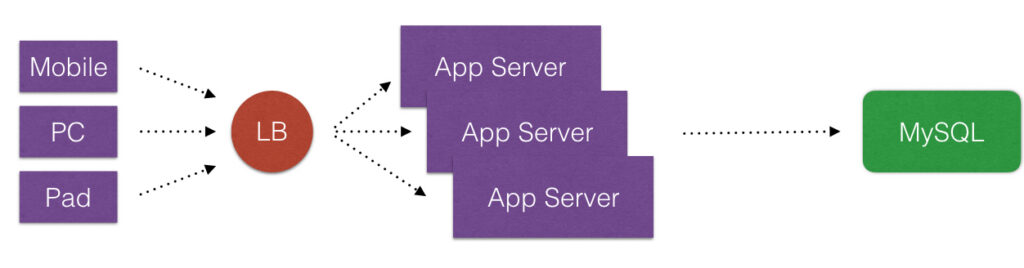
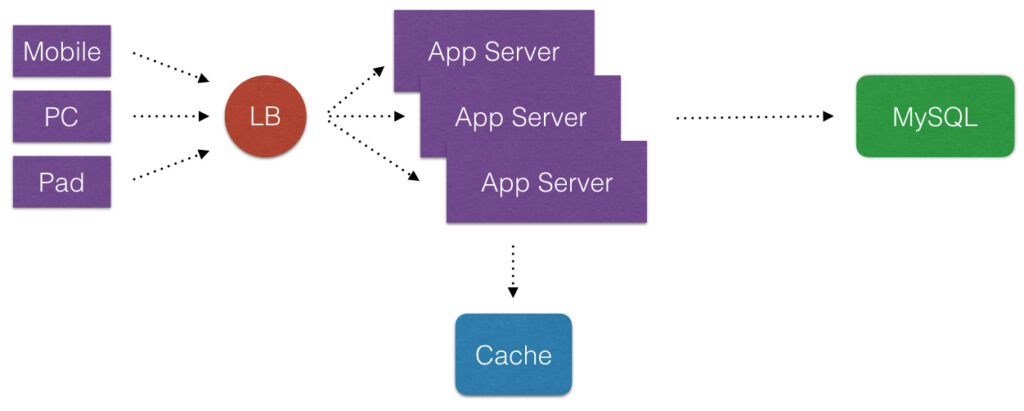
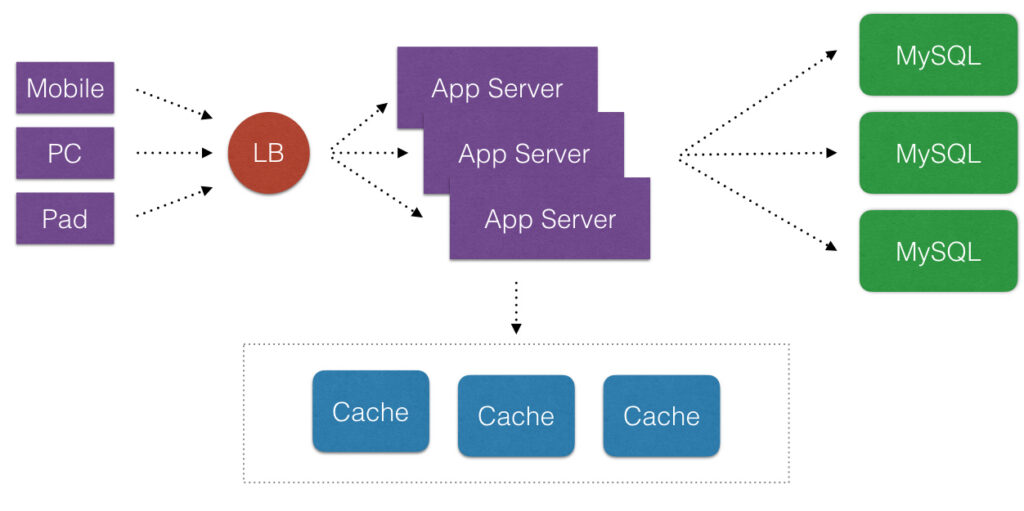
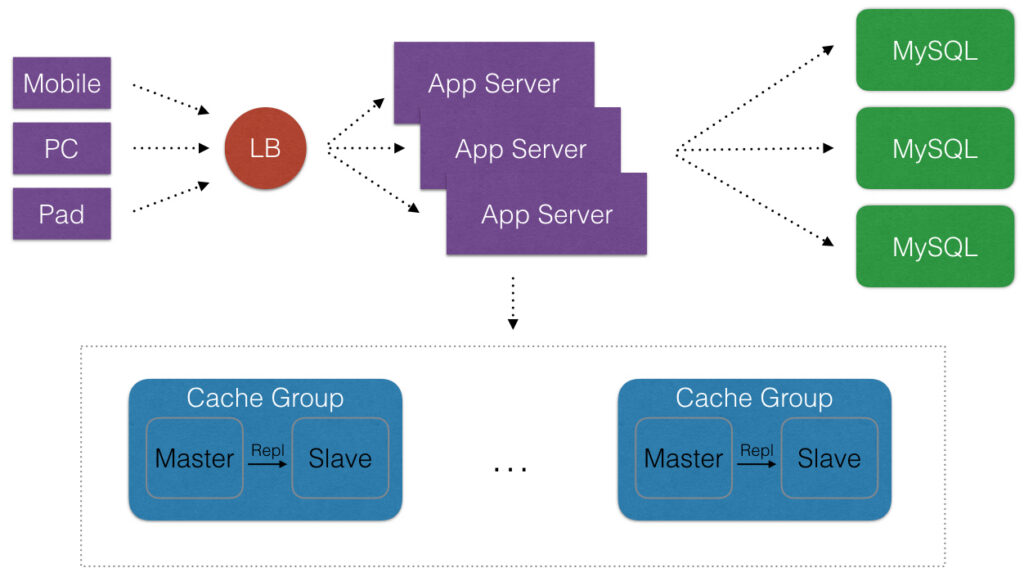
Cache在应用里是一个好东西,使用Cache可以显著地提高应用程序的性能和便于提供应用程序的伸缩性,减少不必要的请求全都打到数据库上。
Cache化目的非常明显,提高应用程序的性能。
Cache作为外部的持久化系统的数据的副本, 仅仅为了提高性能。如果各种DataSource自有的系统性能非常高,那么Cache所能解决的领域就变得非常的少,多加一层会产生更多的不确定性问题。
如果你的数据量非常小用不到Cache,最好的方式是直接不用Cache,查库反而是最方便的。
2.Cache哪些内容?
能够提高系统整体命中率+提高性能的一切数据,均放入Distributed Cache是非常合适的。
归根结底只有一个终极目标,减少查库请求。
例如用户的信息缓存,常见的文章页面,或者秒杀商品详情的缓存。
3.我们想要的Cache产品
从上面的目标和定位推理看一款Cache产品应当满足以下需求:
极致的性能, 表现在极低的延迟, 甚至从ms到us响应
极高的吞吐量, 可以应对大促/大流量业务场景
良好的扩展性, 方便扩容, 具备基本的分布式特点而不是单机
在扩容/缩容的时候, 已有的节点影响迁移的成本尽可能低
节点的基本的高可用,不会出现故障宕机
基本的监控, 进程级别和实例级别等都有关键性的指标
4.Cache使用方式
说到Cache使用方式, 必不可少的会与数据库(甚至是具备ACID的RDBMS)或者普通存储系统对比。
即使Cache有了持久化,但市面上的Cache产品都不具备良好的高可靠的持久化特性, 持久化的可靠性都不如MySQL这类持久化存储数据库。即不能在Cache中存储重要数据。
而使用方式有以下三种:
懒汉式(读时触发)
饥饿式(写时触发)
定期刷新
懒汉式(读时触发)
这是比较多的场景使用,先查询第一数据源里的数据,然后把相关的数据写入Cache。
Java (Laziness)
Jedis cache = new Jedis();
String inCache = cache.get("100");
if (null == inCache) {
JdbcTemplate jdbcTemplate = new JdbcTemplate();
User user = jdbcTemplate.queryForObject("SELECT UserName, Salary FROM User WHERE ID = 100",
new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
return null;
}
});
if (null != user) {
cache.set(String.valueOf(user.getId()), user.toString());
}
cache.close();
}好处和坏处:
- 不太好的是: 大多数的数据可能不再被高频度访问,缓存会浪费
- 比较好的是: 保证数据在Cache里,适用于大多数的场景
饥饿式(写时触发)
Java (Impatience)
User user = new User();
JdbcTemplate jdbcTemplate = new JdbcTemplate();
int affectedRows = jdbcTemplate.update("UPDATE User SET Phone = ? WHERE ID = 100 LIMIT 1",
new Object[] { 198 });
cache.set(String.valueOf(user.getId()), user.toString());好处和坏处:
- 比较好的是: 这种写比例不高数据,写时触发能保证数据比较新。
对比”懒汉式”和”饥饿式”:
饥饿式总保持数据较新
分别存在了写失误/读失误
单一方式的使用都将使Miss概率增加
以上两种各有优缺点, 因此我们将两种结合一下,追加一个TTL有效期
Java (Laziness && Impatience)
cache.setex(String.valueOf(user.getId()), 300, user.toString()); 定期刷新
常见场景, 有如下几点
周期性的跑数据的任务
适合Top-N列表数据
适合不要求绝对实时性数据
Comments NOTHING